提交您的产品
提交您的产品  Ai应用
Ai应用 Ai资讯
Ai资讯 AI生图
AI生图 AI生视频
AI生视频 开源AI应用平台
开源AI应用平台Nanonets-OCR-s:能把图片里的表格转换成Markdown格式模型

Nanonets-OCR-s是什么?
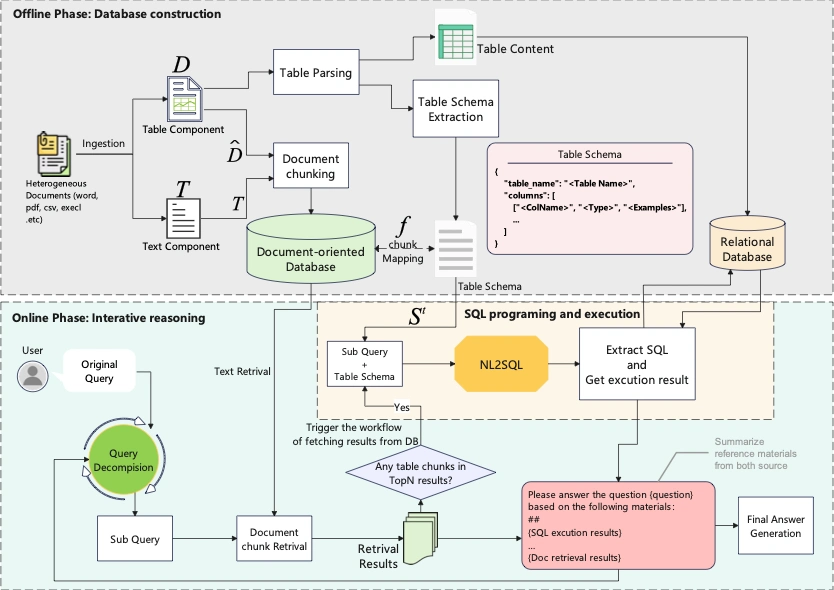
Nanonets-OCR-s,能把图片里的表格转换成Markdown格式,而且还能识别 LaTeX 语法。它还能找到图片的位置,转换成 <img> 标签。签名会被转换成 <signature> 标签,复选框之类的符号会用颜文字表示。它还能处理合并单元格的表格,并输出为 HTML 格式。这个模型大小是 3.75B,是基于 Qwen2.5-VL-3B-Instruct 微调的,所以中文支持得很好。

功能亮点
表格转换:可以精准提取复杂表格,并将其转换为清晰的 Markdown 和 HTML 格式。
公式识别:能够将文档中的数学公式准确转换为 LaTeX 语法,无论是内联公式还是独立公式都能轻松应对。
图像处理:自动识别文档中的图片,并用 <img> 标签进行描述,方便后续处理。
签名与水印提取:可以检测到文档中的签名和水印,并分别用 <signature> 和 <watermark> 标签标记出来。
复选框处理:将文档中的复选框和单选按钮转换为标准的 Unicode 符号,方便阅读和编辑。
使用方式
通过 Python 库:
安装必要的库(如 transformers 等)。
加载预训练模型,然后处理图像并提取内容。
通过服务器接口:
启动服务器,通过 Python 和相关客户端发送请求,获取转换结果。
通过简化工具:
使用 docext 等工具,一键启动应用,简化操作流程。
适用场景
学术研究:快速将论文中的公式、图表和表格转换为可编辑的 Markdown 格式,方便整理和进一步研究。
商业办公:处理合同、报表等文件,提取关键信息并保持格式一致,提高工作效率。
法律领域:识别和隔离签名、水印等重要元素,确保文档的完整性和准确性。
优势
功能强大:能识别多种文档元素,满足不同场景的需求。
智能高效:通过智能识别和语义标记,让输出内容更易于处理。
轻量便捷:模型大小适中,基于现有技术优化,支持中文。
项目地址
https://huggingface.co/nanonets/Nanonets-OCR-s