提交您的产品
提交您的产品  Ai应用
Ai应用 Ai资讯
Ai资讯 AI生图
AI生图 AI生视频
AI生视频 开源AI应用平台
开源AI应用平台FantasyPortrait:单张静态图像生成多角色的情感化面部动画

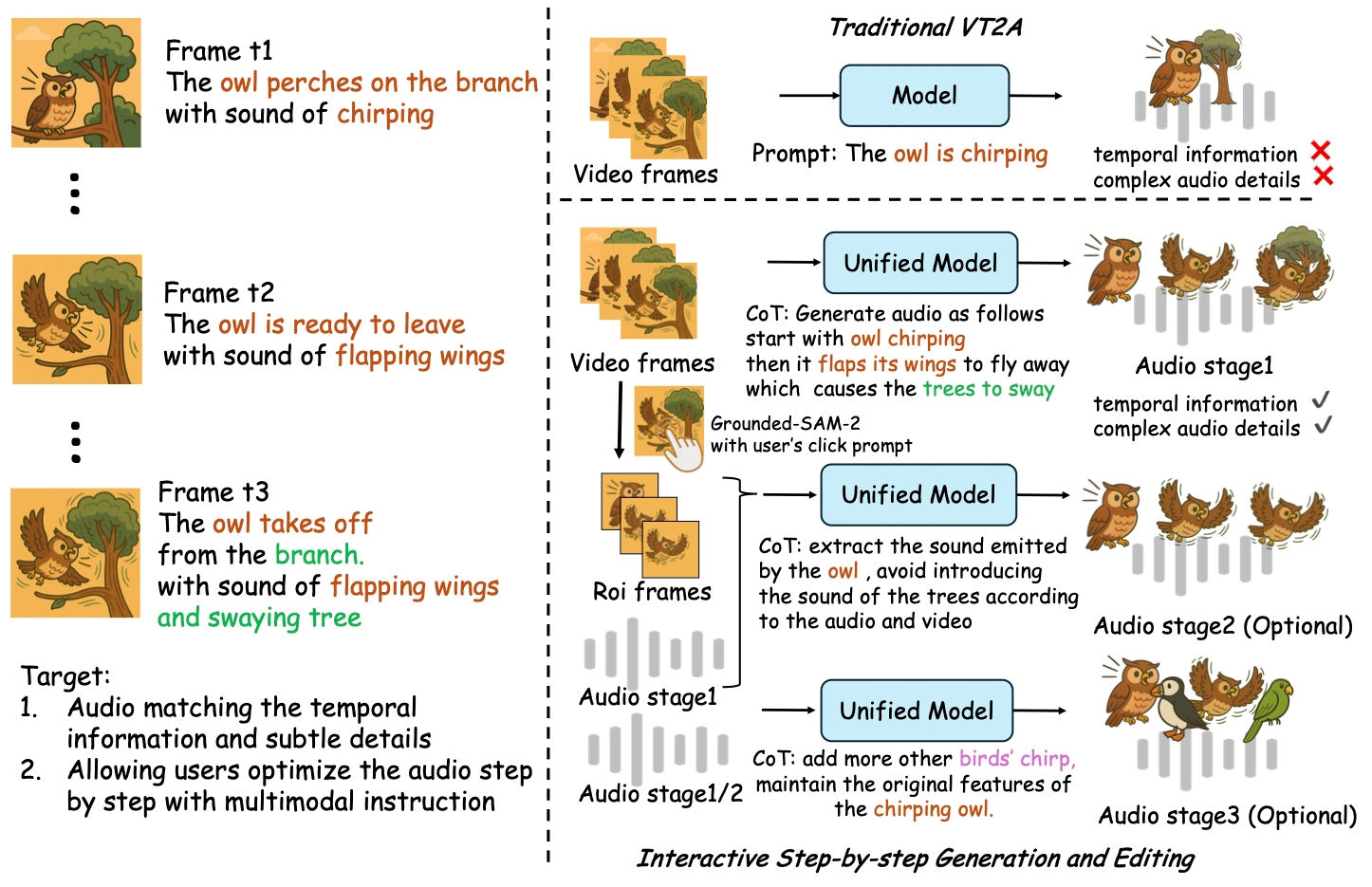
FantasyPortrait 是阿里巴巴高德地图团队和北京邮电大学联合开发的框架,可以从单张静态图像生成多角色的情感化面部动画。它通过隐式特征提取复杂表情,替代传统几何先验,提升跨身份迁移能力,并利用掩码交叉注意力机制避免多角色间的特征干扰。此外,它还支持多风格角色适配、零样本动物动画生成以及低资源音频驱动等功能,适用于数字人、虚拟偶像、游戏 NPC 等领域,代码已在 GitHub 开源。

核心功能
✅隐式表情增强学习:通过隐式特征提取复杂表情,如唇部运动和情感表达,替代传统显式几何先验,提升跨身份迁移能力。
✅掩码交叉注意力机制:为多角色生成独立表情控制区域,避免特征干扰,实现“一人一频道”的协调动画。
✅多模态扩展性:支持文本和音频驱动,例如用 Whisper 编码音频生成口型动画,仅需少量数据微调即可适配多语言。
✅数据集与评估基准:构建了 Multi-Expr 数据集(3 万 + 高质量多角色视频)和 ExprBench 基准,推动行业标准化。
方法设计方面:
✅双阶段训练策略:先通过 UNet 编码表情特征,再通过扩散变换器解码动画序列。
✅多角色控制模块:通过特征掩码隔离不同角色的驱动信号,保持时间维度的一致性。
数据集与评估基准:
✅Multi-Expr 数据集:包含超过 50 万帧的多视角表情数据,是首个多角色动画数据集。
✅ExprBench 评估基准:用于训练和评估多角色肖像动画。
实验结果显示:
✅跨驱动重演任务:相比 StyleHEAT、PIRender 等方法,FID 指标提升 41.7%。
✅多角色动画生成场景:用户偏好率高达 83.5%,能准确生成眼部微颤、不对称嘴角运动等细微表情。
应用场景包括:
✅多角色动画:支持用多个单人视频或单个多人视频驱动多个角色,生成详细表情和逼真肖像动画。
✅多样化角色风格:能生成动态、富有表现力且自然逼真的多样化风格动画。
✅动物动画:虽未在动物数据集上明确训练,但在动物动画任务上泛化能力强。
✅音频驱动肖像动画:通过音频编码和基于 Transformer 的网络将音频特征映射到潜在驱动表示,实现音频驱动的肖像动画,少量训练样本下即可实现良好音视频对齐。
关键问题解答:
技术突破有哪些?
答:一是增强表达隐式控制,通过隐式面部表示学习细粒度表情特征,提升嘴部动作和情感表达建模能力;二是多角色掩码交叉注意力,独创掩码式交叉注意机制,实现多角色独立控制与协同生成,解决角色间特征干扰问题。
功能特点有哪些?
答:包括多角色同步驱动,支持用单个或多个单人视频、一段多人视频同步驱动多个角色;多风格角色适配,能为不同艺术风格角色生成动态流畅、生动自然且风格统一的视频;零样本动物动画,未经专门训练仍有卓越生成能力;低资源音频驱动,可扩展为音频驱动框架,利用 Whisper 编码音频,通过轻量级 Transformer 网络将音频特征映射到潜在驱动空间。
有哪些应用价值?
答:在影视制作中,能让独立动画师轻松生成群戏表演;在游戏领域,可使 NPC 展现千人千面的微表情;在虚拟直播中,能让多角色互动更鲜活自然。
开源信息:
GitHub 仓库:https://github.com/Fantasy-AMAP/fantasy-portrait
项目官网:https://fantasy-amap.github.io/fantasy-portrait/